



Most eCommerce AI projects don’t fail because the model is bad, but because the same small decisions keep being made the same old way – the part most teams underestimate.
The thing about eCommerce is that “I see it, I like it, I want it, I’ve got it” only works on the customer side. For sellers, the reality is very different. Every purchase is the result of a long chain of small decisions: what to show, to whom, at what price, how to fulfill the order, and so on. Each of those decisions has to work not once, but hundreds of times a day.
This is exactly why machine learning found its way into eCommerce. A recent McKinsey survey found that 78% of businesses now use AI in at least one function, with retailers applying it across everything from supply chain management to marketing analytics. ML turns those daily decisions into something measurable and optimizable, based on real behavior. The formula is simple here: you learn from what actually happens, then improve. But before you get there, it helps to understand the fundamentals.
Machine learning and eCommerce: The basics
If you run an eCommerce business long enough, you start noticing a pattern: most “growth problems” are really decision problems. Many of those decisions sit deep inside the eCommerce software development process.
What should the search results show for this query?
Which products should appear on the homepage?
Will you stock out next week, or end up overstocked for a month?
Machine learning helps eCommerce teams answer those questions consistently. Not by guessing. Not by stacking endless rules. It learns from real signals (product data, browsing behavior, purchases, returns, seasonality, etc.) and uses them to guide decisions at scale.
And no, ML isn’t one magic model that “does AI.” In practice, it’s a set of specialized systems, each focused on improving a specific type of decision:
| What ML does | What it produces | Typical business impact |
| Ranks products | Search results and recommendation lists | Higher conversion and revenue per visit |
| Predicts demand | SKU-level demand forecasts | Fewer stockouts and less overstock |
| Scores risk | Fraud/abuse risk scores | Lower fraud losses and fewer chargebacks |
| Estimates response | Promo and pricing response predictions | Better promo efficiency and margin control |
And when those decisions aren’t handled well, the result is predictable: value leaks out of the funnel – often in the same few places every time.

These numbers don’t mean every store is broken in the same way. They mean the same pressure points show up across categories, which makes them a smart place to start. Fix the decisions behind these leaks, and improvements compound.

How Artificial Intelligence Is Revolutionizing the eCommerce Landscape

AR in eCommerce: Application, Benefits, Challenges, and Best Practices

3 Essential Machine Learning Techniques That Businesses Need to Know About
How ML is used in eCommerce today
Machine learning doesn’t arrive in eCommerce as a grand strategy. It shows up as a fix. One by one, teams start automating decisions that used to be handled by rules and intuition. This is where machine learning development for eCommerce usually begins: not with a big transformation plan, but with improving a few high-impact decisions that repeat every day. Investment is rising, too: NVIDIA reports that 97% of retailers plan to increase AI spending in the next fiscal year.
With that kind of momentum, the smarter question is where ML pays back fastest today. Let’s walk through the use cases teams typically start with.

Search relevance and ranking
Let’s say someone types “black running shoes size 10 wide.” If your search treats that like three keywords, they scroll, bounce, and buy elsewhere. If it understands intent and ranks in-stock options that actually fit, you compete on experience instead. ML helps by learning what “good results” look like from real outcomes, so relevance improves over time.
A good reference point is Etsy. They’ve shared how their search ranking evolved over time. First, they used more traditional ranking models and worked on personalization without slowing search down. Later, after a long period of testing, they moved to a unified deep learning model for second-pass ranking. More recently, Etsy also described using LLMs to improve “semantic relevance.”
Personalized recommendations
Search starts with a question. Recommendations start when there is no question at all. This is one of the clearest examples of where machine learning development for eCommerce turns passive browsing into a more guided experience.
Most shoppers browse by jumping between categories. They open a few tabs, compare options, get distracted, and come back later expecting the store to remember what they were doing. We all do that. A recommendation system can learn patterns from that behavior and context. It notices what a customer tends to choose and where their comfort zone sits on price. Over time, it gets better at suggesting the next relevant product, not just a popular one.
BCG notes that retail personalization leaders see revenue growth that is 10 percentage points higher than retailers that lag in this area. Recommendations are not the only reason for that gap, but they are one of the most visible places where personalization becomes real.

How to Implement AI-Based Recommendation System Step-by-Step

Fraud Detection Using Machine Learning: Pros, Cons, and Use Cases
Fraud and abuse detection
Fraud is one of the few eCommerce problems that gets worse over time, because attackers adapt as soon as your rules become predictable. The stakes are rising too. Juniper Research projects eCommerce fraud value increasing from $44.3B in 2024 to $107B by 2029.
That’s why modern risk systems rely on ML for fraud detection scoring. Stripe Radar is a good example of what “production-grade” looks like at scale. Stripe says Radar learns from signals across millions of businesses that process more than $1.4 trillion in payments each year. It uses hundreds of signals to score each payment and reduces fraud by 38% on average.
Demand forecasting and inventory decisions
A promo goes live and demand jumps – perfect. Until the store runs out of inventory exactly where demand is strongest. Suddenly, checkout is full of “unavailable” messages. Marketing did its job – inventory didn’t.
ML helps you react to demand shifts as they happen, so you stock the right items in the right places and reorder before a stockout turns into lost revenue. There’s a reason more teams are investing here: McKinsey notes that applying AI-driven forecasting in supply chain can reduce forecasting errors by 20–50%, and it can translate into a reduction in lost sales and product unavailability of up to 65%.

Machine Learning Pattern Recognition: Explanations and Examples

How to Use AI to Enable Digital Transformation: Overview Across Industries
Pricing and promotions optimization
Demand shifts, seasons change, and inventory pressure builds until it shows up as a pile of slow movers. When that happens, the usual reaction is predictable: you discount broadly, hope for the best, and accept the margin hit.
ML, combined with predictive analytics, gives you a more controlled way to act. Instead of guessing, you estimate what will happen before you touch the price. You can see where a discount changes behavior and where it’s simply giving money away.
That strategy usually comes down to a few repeatable choices:
| Promo decision | What goes wrong | What ML helps you do |
| Who gets a discount | You subsidize customers who would buy anyway | Focus incentives on shoppers who need a nudge |
| How deep the discount is | You over-discount “just to be safe” | Estimate the smallest incentive that still converts |
| Which SKUs get promoted | You push items that don’t need help | Prioritize products with real sell-through risk |
| When to start the markdown | You wait too long, then panic-discount | Predict the moment a markdown becomes necessary |
Build vs buy: What’s better and when?
Choosing between building ML in-house and integrating a third-party solution is rarely about what’s “best in general.” It comes down to priorities. How quickly do you need results, how much control do you need over the decision logic, and how much ownership do you want long term. This is often the point where machine learning consulting is most useful, helping teams frame the decision clearly before committing to a path.
The table below is a quick way to sanity-check which path fits your situation:

When buying a third-party solution makes sense
Sometimes you don’t need a custom ML stack. You need a measurable improvement you can ship quickly, then validate on real traffic. In that case, a third-party solution is often the pragmatic choice. It tends to fit best when:
- You need time-to-value and want to prove uplift quickly;
- You don’t have a dedicated ML/MLOps function yet;
- Your use case is fairly standard and doesn’t require unusual constraints;
- You prefer predictable delivery over building and maintaining custom infrastructure.
Buying works well as a baseline builder. You connect a mature product, feed it clean catalog and event data, and start learning what actually moves your metrics. The catch is flexibility: you get solid defaults, but deeper customization and cross-channel consistency can be harder to achieve. For many teams, it’s still the right first step, especially when the goal is to prove value before building anything from scratch.

AI Integration for Business: A Practical Guide to Efficiency and Profit

From Idea to Launch: The Essentials of eCommerce MVP Development
When building your own ML is the right move
Building your own ML makes sense when it’s part of how you plan to win. This is often where machine learning development for eCommerce shifts from a quick improvement into a long-term capability. It’s usually the best choice when:
- You want search and recommendations to reflect your business strategy;
- You have valuable first-party signals that shouldn’t be flattened into a standard template;
- Your store runs at a level of scale or complexity where tuning by hand stops working;
- You need a proprietary foundation for specialized AI copilot development that understands your specific catalog and customer nuances;
- You need full visibility into how decisions are made and the ability to prove it later.
Building in-house gives you control over what the system optimizes and how it evolves as the business changes. That control comes with ownership. You keep the inputs reliable, the pipelines stable, and performance monitored. When you can run that loop consistently, ML stops being a one-off project and turns into an asset you keep improving.
The hybrid strategy
Hybrid is what you do when you want progress now, but you don’t want to lock yourself into a single path. You use third-party ML where it’s proven and easy to plug in, then you build the parts that shape your competitive edge. The important part is making sure the whole setup behaves like one system with shared data and one experimentation approach.
A hybrid approach tends to work best when:
- You want fast wins now, but you also want a path to long-term ownership;
- You’re okay outsourcing the commodity layer, but not your core growth levers;
- You need flexibility to swap components as your stack matures;
- You want to keep governance and measurement inside your organization, but want to have custom business intelligence tools.
In practice, teams often start by buying fraud tooling while building discovery in-house. Another common path is to launch recommendations with a managed service while you build the event pipeline and testing discipline behind it. Over time, vendor components get replaced one by one, starting with the areas where customization matters most. This avoids a risky “rip and replace,” but still gives you control where it counts.
Machine learning development process
ML projects fail for a predictable reason: they start with a model and end with a dashboard. Production ML works the other way around. You start with a business decision you want to improve and set a measurable target, only then you build the pipelines and models that can hold up in the real world.
Below is a step-by-step process of machine learning development for eCommerce teams.

Step 1: Pick one business decision to improve
Forget “we need AI” for a minute and name the decision you want to improve: something the store makes over and over again. For example, “improve search” is too broad. A workable target sounds more like: “Improve the ranking of search results for high-intent queries in our top category, so more searches lead to add-to-cart.” Now you have a scope, a user moment, and a measurable outcome. The clearer the decision, the faster everything else becomes.
To make it real, you need three anchors:
- A primary KPI you want to move;
- A few guardrails you refuse to break;
- A test scope where you start small.
| Decision you’re improving | Primary KPI | Guardrail metrics |
| Search ranking | Add-to-cart from search | – Out-of-stock clicks – Page latency |
| Recommendations placement | Revenue per session | – Return rate – Bounce rate |
| Inventory reorder | Stockout rate | – Overstock level – Fulfillment cost |
Step 2: Make your data reliable enough to learn from
ML can only learn from what your store actually records, so the data has to explain the decision you’re trying to improve. If your goal is better search ranking, the system needs to see the full story of each search: which products were shown, which ones were clicked, which reached the cart, and which turned into purchases. When impressions are missing, the model can’t tell whether an item was ignored or never displayed in the first place.
That same logic applies to the catalog. If product attributes are messy or inconsistent, the model can’t handle the constraints customers care about, such as size, material, compatibility, or delivery options.
One practical rule: clean only the data that supports the decision you chose. Structure it for your first test, make sure it’s reliable, and then scale from there.

How to Enable Retail Data Analytics: Complete Guide

Customer Churn Prediction Software Guide: What Is It and Why Is It Essential for Business Success?
Step 3: Build a baseline and test it
Before you put your trust in a model, pause and ask a simple question: what would a good version of this look like without ML? That’s your baseline. It gives you something real to compare against, and it often surfaces quick fixes you’d want even if ML never entered the picture.
A useful baseline is a small, intentional set of improvements. For example:
- Cleaning obvious relevance issues in search (synonyms, typos, basic constraints);
- Using simple recommendation logic that matches shopping behavior;
- Setting clear risk thresholds for suspicious checkout patterns;
- Defining rigorous human-in-the-loop benchmarks to evaluate accuracy and safety in generative AI development.
Then validate the impact where it counts: with real traffic. Start small, keep the scope tight, and watch outcomes that matter to the business. A lift that only shows up in offline scoring or click rate usually doesn’t survive contact with real customers.
Step 4: Make machine learning work in live customer flows
Up to this point, ML can still live in experiments and notebooks. This step is where it meets real customers.
In a live eCommerce experience, there is no patience for slow or fragile logic. Search, product pages, recommendations, and checkout all have strict time limits. If ML takes too long or fails at the wrong moment, the customer doesn’t wait – they leave.
So the job here is not “deploy the model,” but to decide how ML runs without getting in the way of buying. That usually means choosing where predictions happen and how the data analytics algorithm behaves when something goes wrong.
Most teams handle this in one of three ways:
| Approach | What it means in practice |
| Precomputed | The system prepares results ahead of time and refreshes them on a schedule |
| Real-time | The model scores the request as it happens, using the current session context |
| Hybrid | Heavy work is done in advance, then a fast scoring step happens at request time |
Whichever path you choose, one rule doesn’t change: the store must stay usable even if ML fails. At this point, ML becomes part of the product.
Step 5: Keep it improving after launch
Once ML is live in customer-facing flows, the work changes shape, which is a core part of machine learning development for eCommerce.
Launch is the first moment your system sees real behavior at full scale. In eCommerce, that behavior never stays still: products rotate, prices change, promotions shift demand, and so on. A model that worked last month can quietly drift out of sync without anyone touching it.
That is why the goal is to set up a simple loop that keeps the system useful over time.
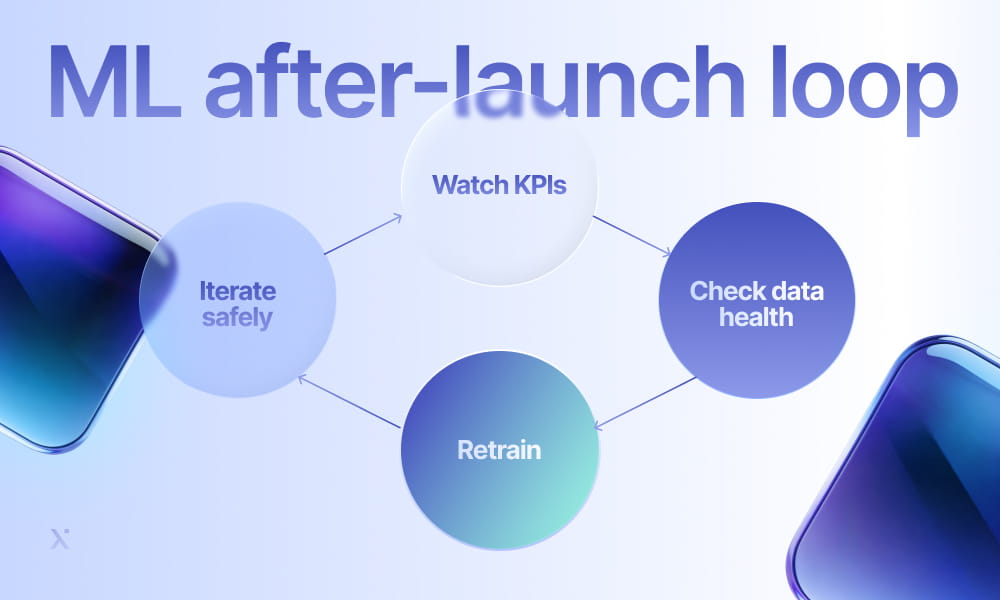
You start with the KPIs you promised to improve: if performance slips, you check data health before blaming the model. In adaptive AI development, when behavior truly changes, you update or retrain, and when you ship changes, you do it in small steps that you can measure and roll back if needed. Then the cycle repeats.
The most underestimated part of ML isn’t the model, but everything around it. Teams usually discover this once the system meets real data and real customers: tracking gaps appear, clean test results become harder to trust, and production requirements demand more work than expected. The biggest surprise often comes after launch, when the system needs ongoing attention to stay aligned with changing inventory and user behavior.

Inside Machine Learning Development: What Businesses Should Know

AI MVP Development: How to Validate Ideas Fast Without Breaking the Budget
Cost to build an in-house ML solution
When you build ML in-house, you’re paying for the entire system that makes it useful in production: reliable data signals, training and evaluation, monitoring, and the iteration loop that keeps performance from drifting over time. That’s why costs vary so widely. Even within common benchmarks, teams often see $30K–$80K for an MVP and $60K–$200K+ for a full production enterprise AI development project, with ongoing maintenance typically adding 15–20% of the initial investment per year.
The final number depends less on how fancy the algorithm is and more on what your business requires. In the sections below, we’ll break down the cost drivers that usually matter most.
Main cost drivers
The surprising part about ML budgets is that the model itself is rarely the main variable. Most costs grow around the system that supports it:
- Making sure the data is reliable;
- Ensuring the logic runs fast enough;
- Keeping performance from drifting after launch.
All of this work continues long after the first model is shipped, because the system has to keep up as the business changes. That’s why data work often dominates the budget.
| Cost driver | Budget share | Note |
| Data readiness | 15–25% | Getting your data into a state where the model can learn from it |
| Model development | 30–40% | Building the model, training it, and checking that it performs well |
| Production engineering | 20–35% | Making the model work inside the real product without slowing anything down |
| MLOps and maintenance | 10–20% | Keeping performance stable after launch as data and behavior change over time |
These ranges are a planning baseline. The actual split shifts based on data readiness and whether the use case requires real-time serving.
Hidden costs
Hidden costs tend to surface after launch, when the system is already in use. Not because something is broken, but because ML systems change as the business around them changes.
Two issues show up again and again in production.
- Training-serving skew. A model performs well during training, then reality shifts. Data changes, pipelines drift, or features behave differently in production. Google explicitly calls this out and lists common causes, including data changes and mismatched pipelines.
- Hidden technical debt. Over time, ML systems accumulate dependencies. More data sources get added. More teams rely on the outputs. Maintenance effort grows quietly, without a single breaking moment.
The practical way to plan for this within AI app development is to treat hidden costs as an annual lifecycle allowance. Many cost guides recommend budgeting roughly 15–20% of the initial build cost per year for ongoing support and optimization. That allowance typically breaks down like this:
| Hidden cost driver | Budget share | Note |
| Monitoring and data quality upkeep | 4–7% | Catching broken tracking and feed issues before they turn into conversion loss |
| Retraining and performance tuning | 5–9% | Updating the model when seasonality, inventory, or customer behavior drifts |
| Production reliability | 3–6% | Keeping the feature fast and stable under real traffic |
| Regression prevention | 2–4% | Rolling out changes safely and avoiding “wins” that break other metrics |
Like the main cost drivers, these ranges are not precise formulas, while the pattern behind them is consistent. The ongoing cost comes from keeping the system aligned with a business that never stops changing.
This is why teams often compare in-house ML costs against third-party integration.

How Much Does AI Development Cost in 2026?

Custom AI Model Development: Tips and Tricks
Cost to integrate a third-party ML solution
Third-party ML can look deceptively simple from the outside: connect an API, get “smart” search or recommendations, done. In practice, the price tag has two parts.
- Integration work, which is the one-time effort needed to make your data usable for the vendor and turn model outputs into something customers actually see.
- Ongoing usage costs, which scale with activity and depend on how heavily the ML system is used in day-to-day operations.
What makes third-party costs swing is not the model itself, but the work required to feed it clean signals and make it behave like a native part of your product. Most retail search and recommendation tools depend on two foundations: product catalog data and user event data.
In the next sections, we’ll break down what actually drives integration effort and where teams most often underestimate the true total cost of ownership.
The three cost buckets you’re paying for
Third-party ML costs are easiest to understand when you break them into three buckets:
- Setup: The work required to get the system connected;
- Usage: What you pay each time the system runs;
- Ops: The ongoing effort to keep it stable and measurable once it’s live.
Setup is usually the most predictable. Usage is the part that scales with traffic and UX patterns, so it’s the one that can surprise you if you don’t model volumes early.
| Cost bucket | How it’s usually priced | Typical cost range |
| Setup | One-time implementation effort | $10K–$50K+ |
| Usage | Metered volume (requests/predictions/ transactions) | $150–$57K+/mo |
| Ops | Ongoing internal effort + optional vendor support tier | ~15–20% of setup per year |
One detail that often gets missed: some costs hide inside these same buckets. Contract requirements and enterprise support usually land under ops, and they can change the total even when usage stays flat. Usage can also spike because of UX decisions. Features like autosuggest or search-as-you-type can multiply request volume without any increase in traffic, which means the bill goes up even when “visits” don’t.
Because small implementation choices compound quickly in production. Running predictions once a day is very different from scoring every search, price change, or checkout in real time. Once traffic volume and reliability requirements are factored in, two projects that look similar on paper can end up in very different cost brackets.
Furthermore, whether you are scaling sophisticated deep learning or LMS development, the infrastructure needs and engineering hours required to maintain accuracy at scale will significantly dictate the final price tag.

Top 10 AI Development Companies in 2026
Top 10 Machine Learning Development Companies
Why PixelPlex: How we deliver ML for eCommerce
ML only pays off when it holds up in the messy reality of commerce. Data is imperfect, traffic is uneven, and edge cases show up fast. That’s why machine learning development services for eCommerce have to focus on what happens after launch, not just on getting a model to work once.
That’s the focus behind PixelPlex’s approach: end-to-end ML systems built to stay reliable from the first rollout through long-term operation.
- Data and integration readiness. ML only works when the inputs are reliable. In our Green Delivery case, the challenge included managing and correctly categorizing a large catalog (15,000+ SKUs) so products are easy to find, alongside operational tooling for logistics and marketing.
- Operational impact where margins are won. The biggest gains often sit beyond the storefront. For a large hypermarket chain, PixelPlex designed a warehouse automation system enhanced with digital twins and an AI-driven order-picking flow, resulting in 80% reduction in order collection time and 95% fewer human errors.
- Commerce-grade experiences that don’t break checkout. ML has to behave like part of the product, not an experiment. PixelPlex built the TON Merch Store as a Telegram Mini App for TON Gateway, focusing on a fast in-app purchase flow and direct payments, delivered on a 5-day deployment timeline.
- Proof-driven delivery. Results only matter if they hold up after launch. Delivery is structured around controlled rollouts, guardrails, and ongoing monitoring, so improvements stay measurable as traffic and inventory change.
All of this sounds good on paper. What matters is how it holds up in real retail and eCommerce environments – and we have real proof.
Smart Mall: AI + iBeacon retail analytics and personalized promotions
Online stores get behavioral data for free. Physical stores don’t. If you want personalization in-store, the first problem is visibility: who went where, what they lingered near, what aisles were ignored. Smart Mall turns offline foot traffic into measurable signals, then uses them to power store analytics and more targeted in-store promotions. Basically “Google Analytics + personalization,” but for physical retail.
What PixelPlex built:
- iBeacon integration and development, including a mobile layer that collects beacon data and supports remote beacon configuration;
- AI analytics logic to generate retail insights and recommendations (heat maps, time-in-zone, promo timing suggestions, discount candidates, etc.);
- Machine learning app development for a cross-platform retailer app and dashboard that updates metrics and recommendations in real time;
- Validation in two large retail outlets.
Kooper: AI-powered smart shopping list with personalization
Grocery shopping is repetitive. Most people buy the same core items, hunt the same discounts, then still end up rebuilding lists from scratch. Kooper is designed to remove that friction: a shared shopping list that learns what you usually buy, surfaces relevant suggestions as you type, and pulls discounts from local stores so the “deal hunting” part doesn’t eat the whole trip.
What PixelPlex built:
- An iOS + Android app built around real-time synced shopping lists;
- A deep learning personalization layer that generates habit-based suggestions;
- Deal/data integration at scale, including integration with 17 retail networks;
- Real data analysis plus ongoing QA/maintenance to keep recommendations reliable after launch.
If you’re exploring ML for search, personalization, or retail operations and want to understand what makes sense for your setup, contact us to discuss a practical starting point.

Top 7 Use Cases and Benefits of Machine Learning in eCommerce

Retail Digital Transformation in 2026: Benefits, Challenges, and Trends
What’s next: The future of ML in eCommerce (2026+)
Agentic commerce becomes a real channel
By 2026–2027, more retailers will be preparing AI agents that can research, build carts, and complete checkout, not just recommend products. Google is already putting structure around this with the Universal Commerce Protocol (UCP), an open standard meant to connect agents with merchants and payments without every retailer building one-off integrations.
Payment networks are moving in the same direction. Mastercard has been publicly framing “agentic commerce” as a trust problem to solve with standards and secure transaction flows.

ChatGPT Integration: How Companies Turn AI Into Real Operational Advantage

What are AI agents? Key Types, Examples, and Benefits
Shopping research moves into chat
For a lot of customers, shopping starts to look less like “search” and more like “conversation.” Instead of opening ten tabs, they ask an assistant to compare options and explain tradeoffs, then bring back a shortlist that fits their needs. OpenAI made that shift explicit with Shopping Research in ChatGPT, which generates buying guides from a user’s needs.
On top of that, Reuters reported OpenAI rolling out shopping upgrades in ChatGPT search, including personalized recommendations with images, reviews, and purchase links. So discovery optimization starts expanding beyond SEO and on-site ranking into a new question: how do assistants interpret and present your catalog?
Operations ML keeps climbing: forecasting and availability become table stakes
The flashy part of commerce AI is the interface. The durable advantage is still operations: forecasting, availability, inventory decisions, fulfillment reliability. As more teams automate storefront decisions through machine learning development for eCommerce, the next bottleneck shows up behind the scenes: keeping the right items in stock at the right time. That’s why demand planning and stockout prevention are moving from “ML initiative” to everyday infrastructure.
Conclusion
In eCommerce, machine learning ends up doing the everyday work of a good store, just at a scale no team could handle manually. When it’s working well, customers don’t notice the technology at all. They just feel like the store understands what they’re looking for.
Of course, it doesn’t run on autopilot. ML still needs people setting goals and stepping in when behavior shifts. The real progress comes from that loop: clear decisions, reliable signals, careful rollouts, and ongoing oversight. Whether you build, buy, or combine both depends on how fast you want to move and how much control you need. If you’re ready to turn ideas into something that holds up in production, PixelPlex ML and AI development team can help you get started and keep improving from there.
FAQ
To get started, you don’t need perfect data or years of history. You need just enough information to describe one real decision and its outcome. That usually means a clean product catalog and basic event tracking that shows what was shown to users and what they did next. If those signals are reliable for a single use case, that’s enough to run a first test and learn. Everything else can be improved once you see what actually matters in practice.
To estimate ROI before building, start simple. Pick one decision you want to improve, like search results in a key category, and tie it to one business metric that matters. Make a rough estimate of what improving that metric would be worth, then test the idea on a small slice of real traffic. A short pilot or A/B test shows whether the change actually moves results, because real customers often behave differently than models predict.
Often, yes, but when it’s implemented well and measured on real traffic. The 2025 AI eCommerce Shopper Behavior Report found a 12.3% conversion rate for shoppers who engaged with AI chat, compared to 3.1% for those who didn’t. Chat helps most when it reduces friction by answering questions quickly or guiding shoppers to the right product. The safest way to know if it works for your store is still a simple A/B test, since outcomes vary by category and data quality.
Early signals often show up within a few weeks, once a small test or A/B experiment runs on real traffic and reaches stable behavior. That’s enough to tell whether a change is moving the right metric. More meaningful, production-level impact takes longer. For customer-facing use cases, that’s often a couple of months. For operational areas like forecasting or inventory, results tend to appear over longer cycles, because they depend on replenishment and fulfillment timelines rather than immediate user actions.
The most common problems aren’t about the model itself. They usually come from starting too big, choosing a vague goal, or relying on data that doesn’t reflect how the business actually works. Teams often try to “do ML” instead of improving one clear decision, which makes success hard to measure. Projects tend to struggle when they skip small pilots, real traffic testing, and ongoing supervision after launch.
You need to be explicit about what “good” looks like and what must not break. That starts with choosing one primary metric that reflects real business value, then adding a few guardrails that protect customer experience or margins. It also means watching real outcomes, not just model scores. ML will optimize exactly what you point it at, so regular reviews and small rollouts help catch drift early.









