



Messenger chatbots have become a proven marketing tool across a variety of industries. Businesses that have not jumped on the bandwagon are missing a piece of the pie.
In our digital age, customers expect to find easy and convenient ways of receiving information about products and services. And what can be better than getting all you need through a live conversation? That’s why most businesses today incorporate chatbots into their customer services, where they assume the role of your typical shop assistant, helping customers pick out clothes, order food, etc.
Chatbots are software applications that rely on natural language processing (NLP) to understand what a person is asking them and simulate a conversation by generating logical responses. Oftentimes they are set up so that they can use humor and other techniques to make the interaction pleasant for the customer and leave them satisfied with the level of service a company provides.
Chatbots have been around for a while, but their development sped up in recent years due to the progress made in artificial intelligence. They’ve become more advanced and versatile, being offered through social media platforms like Facebook Messenger, web-based applications, and even standalone native apps. The pinnacle of their development is considered to be the introduction of virtual personal assistants such as Siri and Alexa.
Read on to find out more about chatbots, how they operate, how useful they can be for businesses, and what goes into building a chatbot.
Dive into what is a chatbot and how it works
Just like with different brands and models of vehicles, what’s underneath the hood of a modern chatbot defines how sophisticated it is. It can be a basic set of algorithms designed to follow a prewritten script of questions, or have a pattern-matching design used to identify what the user is saying and choose an appropriate reply. The most outstanding chatbots are powered by advanced machine learning models and are able to conduct a fluent dialogue with a person.
Rule-based chatbots
Some chatbots operate according to a predefined set of instructions, following them sequentially until they reach the end of the decision tree. These types of chatbots are mostly used by companies in Facebook Messenger to guide customers through their shopping experiences. They use a set of questions to determine the parameters of the product suited for the customer and provide choices of answers with clickable buttons. Some of these chatbots rely on users giving them answers in short text messages and analyzing input based on a list of keywords.
Pattern-matching chatbots
Another design variation is pattern-matching chatbots which use a set of predefined keywords and algorithms to interpret what the user is asking and produce a response. Answers can be given only to a range of questions that were pre-programmed into the pattern-matching chatbot. This type of chatbot can’t go beyond its patterns, but it can steer the user back into the interaction loop by asking them to provide a more direct answer.
For each type of question, there is a specific pattern the chatbot follows based on the information in its database. It analyzes the user’s responses and searches for keywords, matching them with an appropriate response of its own.
These chatbots are a perfect fit for customer support systems and can be used to narrow down a person’s query and delegate it to a qualified expert. The key here is to find just the right moment to turn to a human support specialist and not leave a customer feeling stuck with a clueless bot.
Machine learning in chatbots
Chatbots that use machine learning instead of simple keyword or pattern-matching algorithms are able to learn from conversations with the user and constantly update their knowledge base. They can be made to understand the context of the conversation and also recall their previous interactions. The most popular implementations are based on artificial neural networks that operate similarly to the neurons of a human brain, creating connections and associations between given information.
These types of chatbots break sentences down into keywords themselves and use natural language processing (NLP) to learn the different ways a person could phrase the same idea. Not being limited to just text input, NLP-based chatbots can understand different dialects and accents, and even make their way around mistakes and speech impediments.
Machine learning chatbots train on an existing dataset, and it is on this dataset that the level of intelligence of the chatbot depends. Typically, businesses train their chatbot on a basic dataset of recorded conversations and then let the chatbot interact with users in beta testing for it to become smart enough for commercial use.
Check out our Artificial Intelligence development and consulting services
What kinds of chatbots are out there?

Chatbots are very diverse in their capabilities, their purpose, their domain of expertise, and the platform they are staged on. Choosing the right one to implement depends on the goals you want to achieve, the audience you intend to interact with, and the resources you are willing to allocate for building a chatbot. Let’s go over some of the various types of chatbots used by businesses.
Chatbots can be general-purpose and specialized. General-purpose chatbots are usually well-informed on a variety of topics and are meant to understand user queries. You can ask them what the weather will be like next weekend or for the latest news on space exploration, and they’ll understand what you are looking for. However, they are not equipped to perform any actions or give you the information themselves. Instead, they redirect to an app or another chatbot that is specialized in this particular task or topic.
Google Assistant and Siri are good examples of general-purpose bots. You can ask them pretty much anything and most likely receive a reply. If not, virtual assistants are very good at responding in a humorous way. So you can never be mad about Siri failing to help you.
Specialized bots are often divided into informational, customer support, and action chatbots. Informational and customer support bots converse with users to address their concerns and provide them with knowledge. Customer support bots work well for addressing frequently asked questions and getting into the user’s problem by asking them leading questions. At some point, a real representative can jump in on the conversation to provide qualified help.
Action chatbots or service chatbots assist users in performing transactions. Most customers are already used to having a bot help them book a flight ticket, make a reservation, or place an order for takeout in their favorite Thai place with the chatbot guiding them through the menu.
Based on the platforms where they’re staged, the most dominant now are website-based chatbots and social messaging bots. After Facebook opened its hub to developers, Messenger bots boomed, and now most brands rely on marketing campaigns using chatbots. Other Messenger platforms like Whatsapp, Slack, and Telegram also followed this trend. Website chatbots, which help businesses greet new visitors and create leads, are also common.
Discover how marketers can benefit from AI implementation
How chatbots have become smarter over the years
Modern chatbots are intelligent and some of them can even fool us into thinking we’re having a conversation with a human. Even if they don’t, they do a good job of hiding it behind silly jokes. But it’s been a long path from the origins of chatbots to where we are today. Let’s have a look at the steps of chatbot evolution.
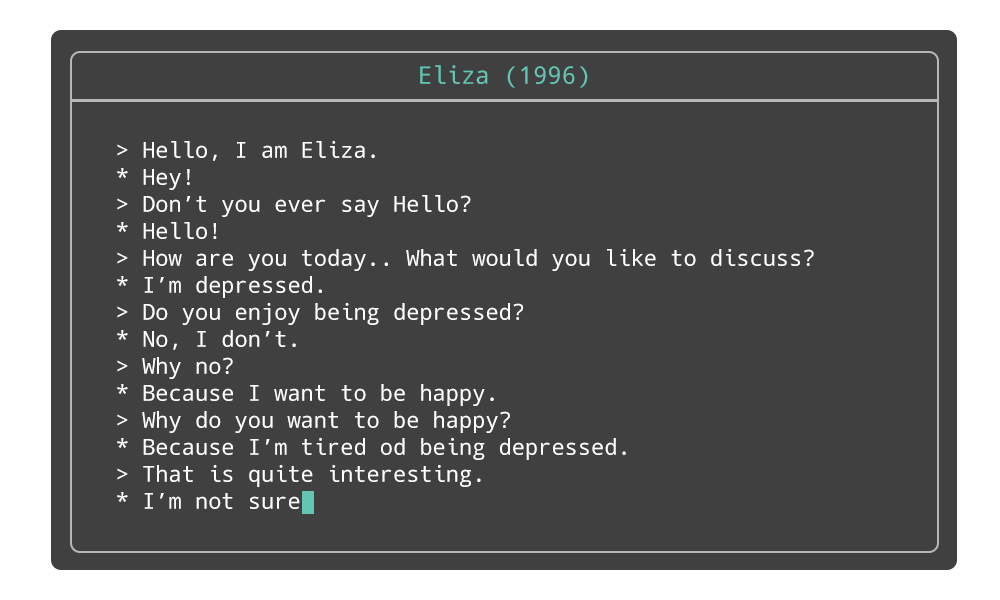
Pouring your soul out to Eliza
Built by the Massachusetts Institute of Technology in the 1960s, a chatbot program named Eliza used keywords and pattern matching to simulate a psychotherapist. Back then talking to Eliza was an uncanny experience as it seemed to be a convincingly empathic conversationalist, giving open-ended replies to a person’s questions. Someone would tell the bot about their feelings or emotions and Eliza would keep the conversation going by asking passive leading questions (like “How does that make you feel?”, “Tell me more about …”). In some cases, people would tell their whole story and feel relieved.
<figure”>
A conversation with Eliza chatbot
Eliza relied on a persona-centered approach called Rogerian therapy which puts patients at the lead of the discussion. It was believed that in this way they would discover solutions to their problems themselves. The approach allowed Eliza to get away with making very little contribution to the conversation and being less intelligent compared to modern chatbot standards.
Having fun with Jabberwacky
The next stepping stone in chatbot development was Jabberwacky, one of the first versions of what is called a ‘chatterbot’. Its main intent was to keep a person entertained by having light conversations on various topics. Created back in the 1980s, it’s worth highlighting that in contrast to Eliza, it could actually keep one or two of its previous responses in memory and ask you questions or generate a statement related to them. Basically, this produced a more natural flow of conversation and made the experience more enjoyable.
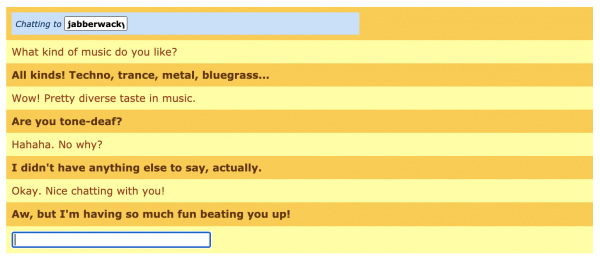
By keeping track of what a user says, Jabberwacky simulates an understanding of the context of the conversation. This is what made this chatbot seem more intelligent compared to previous generations. Jabberwacky was an important step forward and developers to this day are working on perfecting the ability of chatbots to maintain fluent conversations. A working version of this fun bot is still available to play around with.
SmarterChild: first messenger bot
The creators of SmarterChild decided to stray away from the chatterbot concept which was becoming very popular, and chose to build a utility bot instead. It was released in 2001 on AOL Instant Messenger and MSN Messenger. SmarterChild was the first chatbot you could actually ask for something real, like check the showtimes for a movie, get the latest news from Forbes, check the scores for your favorite sports team, or find out about the weather.
By being more than just a conversational bot, able to perform practical day-to-day tasks, SmarterChild helped raise chatbot popularity and bring them to mainstream use. It was an important step in AI software development and the evolution of human-bot interaction.
Watson takes a shot at Jeopardy champions
Moving on to more recent developments, machine learning and natural language processing really came into the limelight when IBM’s Watson chatbot defeated two Jeopardy champions in 2011. With no problem understanding the questions and providing quick answers, Watson showed just how far conversational AI had progressed. It no longer needed a script with predefined generic responses as it has been trained with vast amounts of historical and user-generated data.
Watson demonstrated that it could understand not only the intent of words and their meanings but also make the necessary connections to use variations of phrasing and wordplay. Watson’s capabilities stretch far beyond conventional bots, and its artificial intelligence platform is now used across a variety of businesses in healthcare, retail, financials, supply chain, and many other industries.
Struggling to find the best eCommerce CMS for your business? This overview of the 17 CMSs will help you make up your mind
How smart are chatbots today?

Artificial intelligence and its underlying technologies have helped developers elevate the capabilities and functionality of chatbots, bringing them to a new level. Modern chatbots assist us in getting qualified customer support, performing financial transactions, choosing the right products, and making orders. We are less and less irritated with our virtual assistants as they become much smarter.
The conversational interface of chatbots has advanced immeasurably. Sophisticated natural language processing algorithms allow them to interpret, analyze, and create their own associations between ideas. It also helps process sentiment and even see through typos, misspelled words, and logic mistakes.
Those chatbots that do not require advanced artificial intelligence because of the simplicity of the tasks they perform employ other methods of interaction. Most Facebook Messenger bots use graphic elements to visualize information about products and services and to provide clickable response options. They enable users to share audio, video, images, and attach documents. They use carousels, buttons, and quick reply options to make the interaction swift and smooth.
The current landscape is dominated by virtual assistants like Amazon’s Alexa, Apple’s Siri, Google Assistant, and Microsoft’s Cortana, which bring our fantasies of having a digital friend and helper to life. Asking them to make calls, set up appointments, play songs, and look up information on the web makes using our devices more convenient. With the integration with third-party apps and even more useful features added, there is no doubt that virtual assistants will play an important part in the future of chatbot development.
The unlimited capabilities of AI: see this AI-based shared grocery shopping list app
Business use cases and the value chatbots bring
Chatbots are being used for many tasks, including handling customer support, answering frequently asked questions, and making transactions. Businesses rely on them to provide convenience for their customers by allowing them to easily choose the product or service they need, place an order, check its status, and report any issues to providers. Many brands put chatbots at the center of their marketing campaigns. They are becoming a powerful tool for cutting costs and increasing revenue.
Traditional email marketing sees an average open rate of 14-18% while the chances a customer responds to an ad within the email are less than 3%. With a properly set up chatbot, you can walk your potential customer through the entire campaign in one simple interaction. That is much more effective compared to days and weeks of implementing an email strategy.
Major brands are putting serious effort into making chatbot experiences more convenient, helpful, and worthwhile. According to Uberall, a global leader in location marketing technology, 80% of consumers enjoy a positive experience with chatbots. Crafting such an experience, however, does require customization and fine-tuning – a characteristic skill of a good AI development team.
Roles that chatbots take on
Chatbots can serve businesses to fulfill a variety of needs. Most of the time, they take on one of the following roles:
- Customer support agents. Chatbots can handle simple queries like checking an account balance, changing a subscription plan, or resetting a password. Some can even attend to more complex issues and help users resolve them by giving step-by-step instructions.
- Enterprise employee support. Chatbots can be built into a business’s internal systems, such as enterprise resource planning (ERP), stock management, and customer relationship management (CRM). These bots can help representatives access information within a corporate database, as well as manage new employee training and onboarding.
- Virtual personal assistants. Messenger Chatbots can be used as an easy way of ordering pizza or booking a flight ticket. The chatbot provides you with options and asks you for all the details needed to make an order. Amazon Alexa and Google Home make use of virtual assistants to enable users to control their smart home devices.
This article will tell you how AR and VR technologies can make shopping better
Tasks performed by chatbots
Whatever role a chatbot takes on, it performs a variety of tasks to help businesses address their customers’ needs. Let’s take a look at what chatbots can do to give you a better idea of their capabilities:
- Making orders online. Instead of leaving. Instead of leaving users to browse through your catalog or menu for an hour, you can use a chatbot to accept their order in a more engaging and conversational way. Chatbots can provide options to choose from based on preferences or even ask the customer if they want to repeat their last order.
- Scheduling meetings and appointments. A bot can take over the tedious task of organizing and confirming a meeting between several people. You may ask something like “I would like to schedule a meeting with John and Esther for 6pm Thursday”. A chatbot will first confirm the meeting with them and then set it up in your calendar.
- Collecting customer feedback. Chatbots can ask customers whether they are satisfied with their last purchase or with the services provided. It’s also a good way of keeping customers in the loop and offering related products that they might like, based on their feedback. Businesses can store and analyze this information to improve the product’s quality.
- Sending product-related notifications. Chatbots can notify customers about upcoming releases, special offers, and new product features. Many brands rely on customer opinions to bring out products that satisfy them most. You can launch a campaign promoting a new release with polls asking customers how much they’re looking forward to it.
- Making personalized recommendations. A chatbot can use other services to analyze a customer’s browsing habits and behavior and provide them with a personalized offer. This could be really worthwhile, especially if a bot recommends something a customer was having trouble finding.
- Delivering news. Chatbots can deliver news summaries and invite users to read more by following a link. Users can even ask for a certain topic or subscribe to several topics based on their interests.
These are just a few of the possible use cases. A chatbot’s behavior can be customized for the industry and the business’s marketing intentions. Ultimately, it’s a great tool for engaging with customers and increasing conversions.
Real-life examples of chatbots used by businesses
Chatbots serve a variety of purposes. Different types of companies use shopping bots, financial bots, customer support bots, health bots, therapy bots, marketing bots, and more. You can spend hours talking to a conversational bot for plain entertainment, plus save time and order some pizza in a matter of minutes. New bots are being created every other day. Let’s have a look at some interesting examples.
Sophia: a great AI conversationalist
Let’s start with a project that is not truly a chatbot, but it’s fun to bring in as an example. Sophia, created by Hansons Robotics, is a conversational social robot that represents the dreams of future AI. Being able to participate in live conversations with people, Sophia can give unique responses in every new situation or interaction. Machine perception technology allows her to recognize human faces as well as understand emotional expressions and hand gestures. She can also make them herself, so speaking to her is quite an engaging experience.
Sophia’s character has raised awareness and captured the excitement of a global audience. She was able to do what no chatbot is yet capable of. Sophia travels around the world and speaks on important issues of humanity like global hunger and environmental issues. She is an Innovation Ambassador for the United Nations Development Programme and has become the first robot citizen. She had quite a lot of media exposure and was even featured twice on the Tonight Show with Jimmy Fallon.
Take a look at this smart retail solution powered by AI & iBeacon technology
Answer Bot: a chatbot for business
Let’s move on to a helper that’s a bit more serious. Answerbot from Zendesk is a tool that you can use to augment your customer support service. Mostly it’s a pattern-matching bot, although it does utilize some elements of machine learning. Answerbot can work alongside a business’s support team to answer common questions and identify the customer’s intent. If it can find the answer in its database, it will find a perfect time and approach to bring in a human agent.
This chatbot mostly handles low-priority customer support tickets, relieving your team from working on the same types of questions over and over again. A good thing about Answerbot is it’s easily set up and can be configured in just a few clicks. It also supports many channels that your business is likely to use, such as chats, messaging apps, email, and even techy ones like Slack.
Madi: a hair color matching bot
Madi is Madison Reed’s helpful chatbot that assists customers in choosing the perfect hair color product. What sets this bot apart from others is that it provides you with a personalized color match. Madi does this by asking customers to submit a selfie. Being an absolute hair wizard, it analyzes your primary hair color as well as any additional tones. After that, the chatbot asks several additional questions about your hair and preferences to narrow down a list of perfect options tailored just for you.
The neat thing about Madi is that it speaks the brand’s audience’s language. It uses flattering comments as well as “x’s and o’s” that would naturally appeal to women. It’s very humorous and witty and it almost feels like you are talking to a Facebook friend. Its ultimate goal is to create a connection with the customer and sell the product. Madi provides a personalized color match and a list of recommendations of different shades that might also interest the customer. After the customers make their pick, they are instantly redirected to the website to finalize their purchase.
Domino’s bot: when the time comes for pizza
Some of you might have gotten a bit hungry with all this reading. Well, here’s a chatbot you can use to sate your appetite. Dom the chatbot is always ready to take your order and entertain you in the process. Customers can use it to reorder their previous basket, choose something new from the menu, and track their pizza deliveries. Because there’s hardly anyone who doesn’t like pizza, Dom has become one of the most popular Facebook Messenger bots.
Insomnobot 3000: fighting insomnia
If you’ve ever suffered from insomnia you might have experienced the terrible negative thoughts and worries that creep in, making you feel miserable and, most importantly, leaving you unrested and exhausted the next day. Luckily there’s a digital buddy that can help get your mind off your troubles and fall fast asleep. Insomnobot 3000 is an off-beat chatbot obsessed with nighttime snacks that keeps insomniacs company during the dreaded hours.

Funny story: the chatbot was initially created by Casper, a company that sells mattresses and sheets, as part of its marketing campaign. The Insomnobot struck a chord with users and became quite popular, also catching the attention of the media. It’s a good example of how a non-service-oriented chatbot can also have a positive impact on your business.
Practical guide on how to build a chatbot

To understand the process of developing AI-based chatbot architecture, let’s take an example of a real-world implementation. IBM Watson, for instance, was based on DeepQA architecture using NLP and machine learning. DeepQA architecture was responsible for most of the work done by IBM Watson. It was used for generating hypotheses, gathering massive evidence, and analyzing the data.
The DeepQA team used the following methods to build the chatbot:
Content Acquisition
Content Acquisition was done manually but also included automated steps. Analyzing example questions is a manual task while domain analysis is performed using automatic or statistical analyses, such as the LAT analysis.
The first step is to analyze example questions from the problem space to produce a description of the kinds of questions that must be answered. This is referred to as answer type detection and is a fundamental step to be taken before moving towards further answering.
Question Analysis
Question Analysis is the process of understanding the user query. There are multiple steps involved in performing Question Analysis which include various NLP functions like tokenizing the question, entity extraction, and focus detection. All of these operations will be helpful as clues to generate the answer.
Moreover, the questions are classified on the basis of the type of problem being asked, like logic puzzles or computations, etc. Using LAT to find clues from the question to start the processing is part of the question analysis.
Hypothesis Search
Hypothesis generation is performed in several steps. The primary search uses a keyword evidence-based search and considers the top 200 instances of the answer received. Analysis shows that most of the correct answers come from these 200 samples. Thus, candidate answers (CAs) are generated using these primary searches.
Filtering of the primary samples is done using models to decrease the number of samples. Hence, if the answer is not valid from the reduced set then the leftover answers from the primary searches are used again. Each CA is then put back into the question to be used as the hypothesis for the answer. If there is a failure at this stage, the system reconsiders, recalls the other pipeline and works with that pipeline again.
Evaluating the Generated CAs
The next task is to generate the support vector that is the evidence for the support of each answer. This can be done using passage search or evidence generated during the keyword evidence search used to provide the evaluation criteria for each CA. The score for each of the candidate answers is then evaluated and given a rank that increases the probability of finding the correct answer early on in the process.
Final Merging
In this step, the merging of the hypothesis is carried out based on the evaluated scores. This is done because answers from various platforms may be equivalent to be produced as an output. An ensemble of matching normalization and co-reference algorithms is used, which helps in the selection from the equivalent answers.
Ranking
The final step is to rank all the hypotheses and build the confidence score for each of them. Then, the hypotheses are run over the trained ML model to find answers to the questions. The models are trained on the predefined hypothesis generated from the present domain knowledge and all the data available at the time of the model training. This model generates prediction results to provide the answer to the question asked.
Conclusion
In a world driven by social media and a constant thirst for sharing experiences via digital channels, businesses need to turn their marketing strategies around and focus on communicating with their customers.
People demand an instant response on their orders and customer support queries, and want an easy way of receiving information or tracking a delivery. The simplest way is a live conversation. Having live agents and operators, however, is costly. Chatbot customer support and marketing allows you to cover more communication channels and reduce your expenses. They deliver quick responses to customers’ queries and also often provide an entertaining experience.
Although there are platforms that provide a simple interface to create a chatbot from templates and building blocks, they may lack the flexibility to cover all of your business needs. A custom-built chatbot can be tailored to suit your brand image and marketing objectives. An experienced AI development company will point you to the right chatbot design for your business case and create a personalized experience for your customers.







